
生物制造是一种利用工程化生物系统生产高价值化学品和药物的技术,其核心在于通过合成生物学优化微生物工厂以实现高效生产。然而,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。大语言模型(Large Language Models,LLMs)作为一种突破性的生成式人工智能技术,因其在知识生成、数据挖掘和复杂问题解决中的卓越能力,为生物制造带来了新的希望。目前,LLMs在合成生物学中的应用尚处于探索阶段,特别是在知识合成和智能化生产中的潜力尚未被充分挖掘。
近日,中国科学院天津工业生物技术研究所生物设计中心开发了基于大预言模型(LLMs)的SynBioGPT菌种改造专家系统。
SynBioGPT整合了51,777篇文献摘要和23,318篇开放文献,可以用于查询问现、基因突变、产品查询和竞争途径探索。
目前,团队还打造SynBioGPT线上版本,用户注册后就可以体验。
地址:https://synbiogpt.biodesign.ac.cn

团队还表示,未来大语言模型将会彻底改变代谢建模和工程中的设计-构建-测试-学习 (DBTL) 周期,还将在生物制造中实现自动化实验室。
SynBioGPT
SynBioGPT模由中国科学院天津工业生物技术研究所生物设计中心马红武联合圣路易斯华盛顿大学Yinjie J. Tang研究团队共同发表。
当前,预训练好的模型基座+知识数据库是普遍的解决方式。从合成生物学文献中选择特征,这些特征是设计和预测生物制造性能的影响力因素。
尤其基因组学研究的测序数据(DNA/RNA/蛋白质)对语言模型具有天然的亲和力,非常适合整合进入大语言模型。
于是团队结合检索增强生成(RAG)后,大模型的回答准确性从25%显著提升至85%,其中Qwen1.5和Llama3模型表现尤为突出。为了进一步验证LLMs在生物制造中的应用潜力。
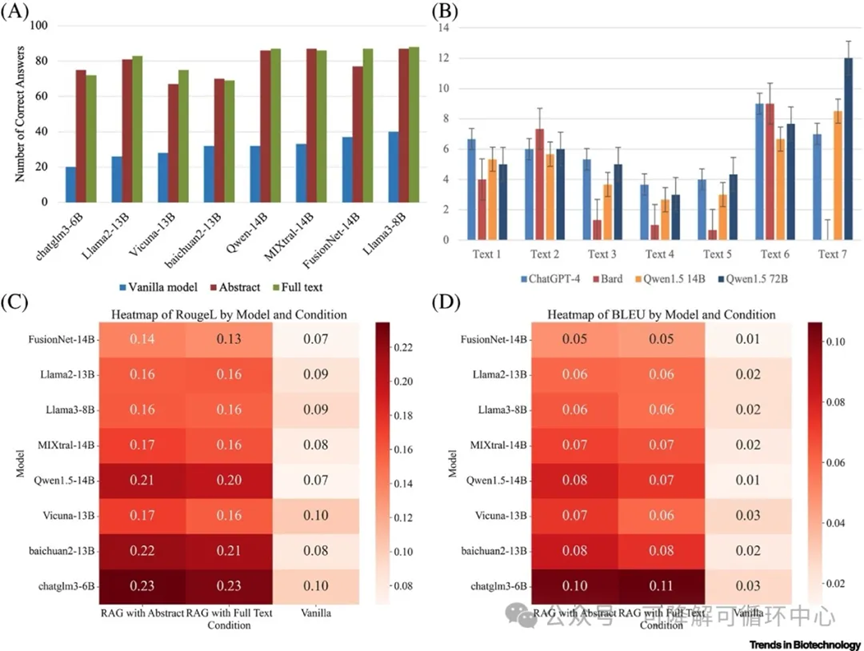
大语言模型(LLMs)在合成生物学知识抽提和智能问答任务中的比较
大语言模型前景广阔
赋能DBTL
细胞工厂的开发离不开酶工程、途径设计和发酵优化,而DBTL(设计-构建-测试-学习)循环则是研发关键环节。
大语言模型可以为菌株工程提供有效策略。最近的一项研究证明,LLMs可以通过从超过29,000个条目中提取大规模代谢工程方法来增强DBTL循环,涵盖1210种产品和751种生物体。
另一项研究表明,具有RAG的模型不仅可以为酵母途径工程提供遗传靶点和实验设计,还可以引导新的生物合成途径假设。
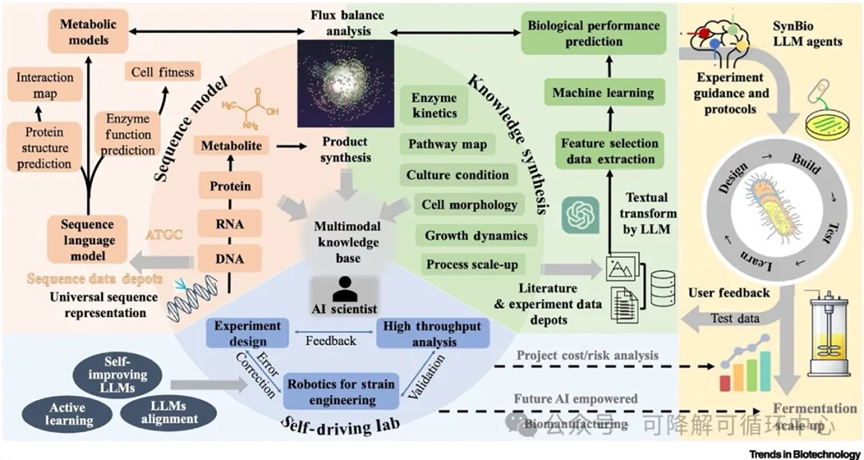
大语言模型(LLMs)可将菌株开发的设计-构建-测试-学习(DBTL)过程整合为一个统一且高效的流程
此外,LLMs可以与白盒模型(如基因组规模模型(GSM)和技术经济分析(TEA))集成,这可以扩展其推理能力并助力生物制造的商业决策。
基于AI Agent的自动化实验室
未来大语言模型作为智能代理,将进一步赋能生物制造,减轻研究人员的劳动强度。
具体而言,“AI科学家”是一种新型智能系统,利用大模型协助人类科学家进行大规模分析和重复性DBTL任务执行。
首先,大模型可以通过将复杂任务分解为子推理步骤来协助任务规划。例如,ChemCROW利用“思维链”推理循环将复杂任务分解,并识别与物理世界交互的相关工具。
其次,大模型可用于自动化实验设计和规划。此外,大模型还能支持信息组织、子任务推理、复杂任务工具选择、实验协议准备和数据分析。第三,基于LLM的知识检索器可以与云计算和硬件控制集成,为自动化实验室测试提供更大的灵活性和可扩展性。
当前大语言模型在生物制造产业中的应用并不广泛。
主要还是面临着多模态和非结构化数据整合的问题,包括表格、图像等数据,此外,从文献图表中提取时间序列数据仍是难题。
而未来真正的应用,需要学术界和工业界的共同推动,研究出更多的计算工具和研究范式。
